Exercice :
- Faire dans le tableau une nouvelle colonne avec le dump-text des pages aspirées grâce à la commande lynx.
- afficher avec la commande file (option -i pour plus de lisibilité) le charset
- Déterminer si le mot recherché (ici le mot vacances) est toujours présent dans le dump-text. Cela permet d'écarter des URLS dont on ne peut pas aspirer la page.
Voilà le script utilisé :
La commande
lynx fonctionne très bien,
file également.
J'ai essayé la structure conditionnelle suivante pour déterminer si "vacances" se trouvait toujours dans le dump-text :
mot="vacances"
dump=../DUMP-TEXT/$j/$i.txt
case $mot
in
`
cat $dump`) echo "<td align=\"center\" width=\"50\">OK</td></tr>" ;;
esac
Donc je demande au script de regarder dans le contenu de chaque fichier dump-text (cat $dump) si le mot vacances est présent. Cependant, cela ne fonctionne pas. Je crois que c'est parce qu'il ne faut pas qu'il y a d'espace dans la partie entre
in et
) et j'en mets un entre le
cat et la variable.
J'ai donc essayé la solution suivante avec un alias, sans résultat non plus :
(cf la partie sur les alias
ici)
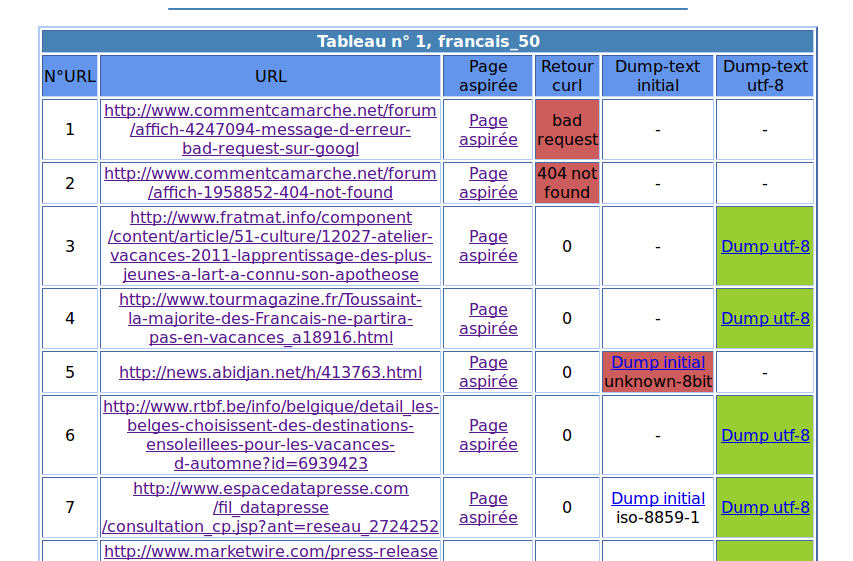
Le tableau suivant a donc été créé :
Pour le dump-text j'ai juste eu un problème. Même si il est en UTF-8, mon navigateur lit les pages en ISO par défaut et j'ai ce type de page qui apparait :
En changeant manuellement l'affichage, les caractères spéciaux s'affichent normalement comme ceci :
Je n'ai pas réussi à trouver comment forcer firefox à lire les pages en UTF-8.